- 1.What is Hypertext Transfer Protocol (HTTP) anyway?
- 2.Ultimate Guide to Understanding HTTP Status Codes – 400 Series
- 3.Ultimate Guide to Understanding HTTP Status Codes 500 - Internal Service Error
- 4.Ultimate Guide Understanding HTTP Status Codes - 300 Series
Series - part 1 of 4
What is Hypertext Transfer Protocol (HTTP) anyway?
The world wide web, as we know it today, was invented by a scientist at CERN, the European Organization for Nuclear Research, named Tom Berners-Lee.
The creation of the World Wide Web was refined through the years of about 1988 – 1991. HTTP is an ongoing technology and will always be under refinement as consumer demand tests current HTTP specifications.
Originally, HTTP mechanisms were designed for allowing scientists from around the globe to share a research and collaboration platform. As it turns out, the world wide web has put publishing, learning and collaboration tools in the grasp of anyone with a VOIP phone.
The original components behind Mr. Tom Berners-Lee’s invention are still in use today. As a matter of fact, some modern day web-servers still understand the original HTTP specification (even though considered obsoleted today):
Basic Components of the World-Wide-Web:
- a web server
- a user agent
- textual display
- Media Types
- a protocol allowing transfer of documents, HTTP
| Modern Day W.W.W. | |
| web server | IIS, Apache, NGiNX |
| user agent | CuRL, Chrome, Firefox, RSS Readers |
| textual data | UTF-8, ASCII, JSON, HTML, XML, CSS |
| media types | textual data, images, video, animations |
| HTTP specs | HTTP 1.1 & 2.0 |
Two primary entities are tasked with defining modern HTTP progression:
-
W3C World Wide Web Consortium The W3C is concerned with the functionality of web-servers, future specification needs, user agents (or web browsers), HTML, XML, video, images and content delivery technologies. More or less, the W3C is concerned with effects of HTTP on the Application Layer.
-
IETF Internet Engineering TaskForce IETF is concerned with how HTTP will work and function on a lower technical level. HTTP works on the top of underlying technologies such as IPv4, TCP, UDP, Ethernet and much more lower layer protocols. All lower protocols work together in getting data from user-agent to web-server, back to the user agent.
How are Standards Like HTTP Defined?
When an Internet protocol like HTTP is adopted or revised standards are defined in documents called an RFC.
RFC stands for Request For Comments.
Every recognized data-communications protocol accepted for mainstream Internet usage will be defined in a series of RFC documents. Technologies like HTTP, IPv4, TLS, PKI, SNMP, POP3 and even Ethernet are not technologies owned by Microsoft, Apple, or Google.
Standards defined in an RFC are meant to be adopted as means of allowing communications across multiple vendor platforms. Each technology (at its core) documented in a RFC can be implemented, refined for use, and even added to products by any person or vendor free of royalties or patents.
An RFC is usually a rather dry document available in ASCII text, keeping with the tradition of being readable across any platform. An RFC will also assume the reader proficient in technical concepts.
- RFC 7540 the HTTP 2.0 specification: RFC7540 HTTP 2.X
HTTP is an acronym for Hyper Text Transfer Protocol. HTTP is a stateless, application layer protocol designed for communicating exchanges of information between systems across the Internet. As such, HTTP defines a set of rules allowing both transfer and access to remote documents. HTTP also has been used for transferring information in other ways such as SSDP which uses UDP and multicast addressing (adopted as HTTPU) for information transfers.
What HTTP is NOT?
HTTP and the world-wide-web are not the Internet. HTTP is a protocol powering an extremely popular portion of the Internet known as the world wide web.
HTTP operates above underlying network communication protocols in the TCP/IP model. TCP/IP is a mechanism for transferring data, framing information, and application layer data over the Internet. HTTP is an application level standard specializing at transferring a certain type of data. As such, HTTP can be used over any data-communications-model such as IPX / SPX or TCP/IP. In today’s world, however, TCP/IP is the reigning king of computer networking protocol suites.
TCP/IP is a data-communication protocol suite developed by the Department of Defense from the USA. TCP/IP may sometimes be referred to as “the DoD networking model*.
In its early years the Internet and TCP/IP were donated from DARPA labs to academia. After being refined for academic use the Internet was adopted by consumers and corporations to become what we know as the Internet of today. It was during the period of transition from academia to early public use HTTP and the world-wide-web were introduced.
- When thinking of the entire Internet think of TCP/IP.
- When thinking about the World Wide Web think of HTTP.
How Does HTTP Fit Into This Whole TCP/IP Thing?
| TCP/IP | Layer Protocols |
|---|---|
| Application Layer |
|
| Transport Layer |
|
| Internet Layer |
|
| Link Layer |
|
The above table is a representation of how HTTP fits into the Internet and TCP/IP. Some protocols in the TCP/IP model can take months of specialized training to master. HTTP, however, is quite simple to use and learn.
The above table is a representation of how HTTP fits into the Internet and TCP/IP. Some protocols in the TCP/IP model can take months of specialized training to master. HTTP, however, is quite simple to use and learn.
Specifications For HTTP
Primarily, HTTP is for communicating transfers of documents between a user agent and web server.
HTTP exchanges usually consist of the user agent requesting a series of documents from a web server. When an HTTP request is received by the web server it will analyze the request. Finally, the web server either returns a document and status code or may deny a request by returning a status code as to why a request was denied.
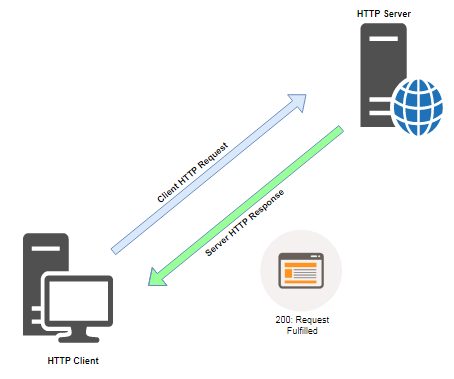
Successful HTTP Request
- For details specific to why a web server may deny a client request please refer to HTTP 400 Status Code section

Ultimate Guide to Understanding HTTP Status Codes – 400 Series. 400 series request codes deal with malformed and unserviceable requests from a user-agent. Whenever a 400 series is encountered the problem is usually on the client side.
Read More
User-Agent is a fancy term given to an application requesting HTTP resources from a web server. Most commonly user agents are known as a web-browser. However, RSS Readers, Web Scraping Bots, web spiders, and HTTP libraries like CURL are user-agents as well.
Web Server is a daemon commonly running on port 80 specifically purposed for retrieving documents from a designated portion of the server’s filesystem for delivery to a user agent.
The three most common high-load web-servers on the Internet today are Apache, Nginx (pronounced Engine-X), and IIS (from Microsoft).
Let’s look at a simple HTTP request with a user-agent application named Fiddler.
Fiddler is a free Windows.Net Application (with MacOS and Linux apps in Beta) for debugging HTTP API’s and web applications. Fiddler is used by many developers and security testing professionals. It is a great tool for exploring the inner-workings of HTTP.
Tools like Fiddler are often used for debugging web applications.
HTTP Request Methods
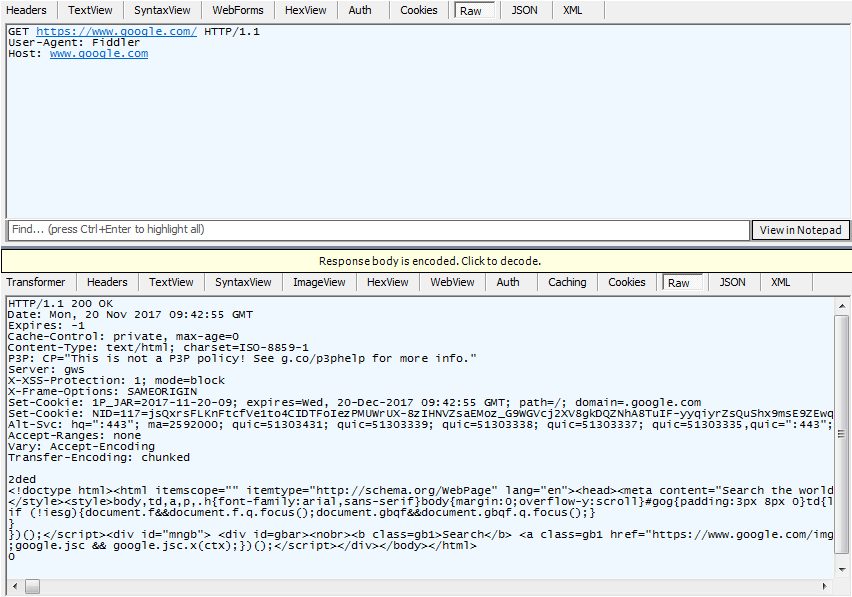
The graphic shows HTTP request and response exchanges with content just like when “https://www.google.com” is entered into a common web browser
Just as displayed in the first diagram of an HTTP request/response exchange, the user-agent requests a document then a web server fulfills a valid HTTP request.
Shown in the top portion of the Fiddler UI window, Fiddler, the user-agent sent three lines of data:
- GET specifies file and path
- User-Agent identifies client software
- HOST specifies host where content is located
The Request Method is GET in this request. We will learn of other HTTP Request Methods in this primer.
The User-Agent String: A User-Agent string is how the web-client software identifies itself to the web server. API’s and websites will often grant or deny access privileges and display-settings based on the client’s User-Agent string.
When scraping a website, developers often look at the robots.txt file to identify how user-agent strings are permitted to access a site. Changing to a user-agent imitating Google’s web spiders will sometimes grant permission to content otherwise disallowed to the general public.
| Some common User-Agent strings are: | |
| Chrome on Windows 7 |
|
| Internet Explorer 11 |
|
| Googlebot |
|
| Play Station 4 |
|
If you don’t like teasers displaying only partial content without a paid subscription on some content sites, try switching the user agent string in your browser to simulate a GoogleBot.
Most content-providers allow Google’s spider-bots full access for archiving content to lure web-surfers from Google searches.
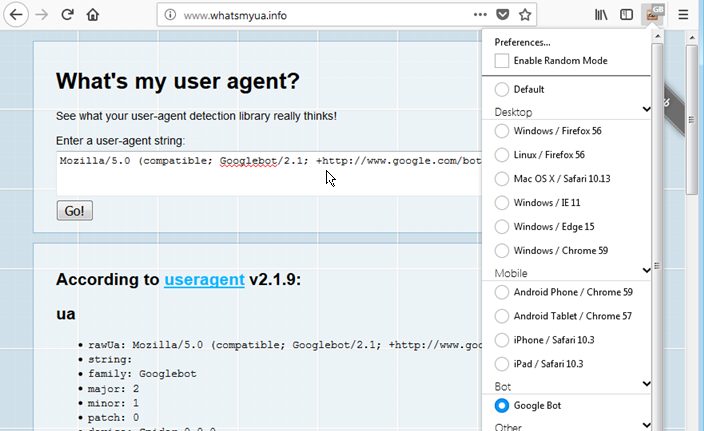
Using the User Agent Switch Add-On in FireFox
Host
The Host header specifies the server (and domain) which possesses the requested document. As of HTTP 1.1 (still commonly used today) the host field is required. HOST is required because most corporate websites, for security, are now hosted virtually on a single extremely powerful server.
A host IP address of 192.168.1.98 may have an external DNS name of web3.biga-hosting.com. This server named web3.biga-hosting.com can host hundreds of domains. In turn, the HTTP host header will let the server know to which hosted domain a request is destined. Multiple virtual domains can have the same IPv4 address of 192.168.1.98 (reverse DNS will usually point to web3.biga-data.com).
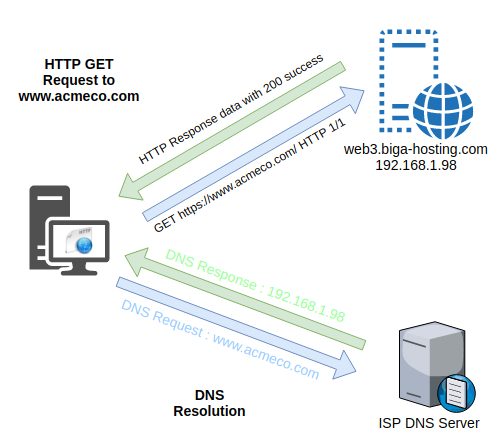
GET request to a web server hosting multiple domains
Dissecting HTTP
This section will delve a little deeper into interworkings of the HTTP Protocol. Topics discussed giving an overview of HTTP include:
- URI and URL concepts
- HTTP Verbs:
- GET
- POST
- PUT
- DELETE
- HEAD
- TRACE
- OPTION
- Media Types
- Common HTTP Characteristics:
- stateless and sessionless
- no encryption built in
- HTTP Authentication
URI and URL Concepts
Of all concepts encompassing HTTP deciphering the terms URI and URL are simple yet still confusing amongst both students and even some developers. To further confuse a simple concept the term URI has been refined and documented in standards allowing the term URL to be synonymous with URI.
URI is an acronym for Uniform Resource Identifier URL is an acronym for Universal Resource Locator
I will try to define each in the most simple terms possible using an analogy. In our scenario let’s say URI is analogous to the term automobile. A URL is a specific type of URI. So let’s say URL is analogous to a “car” but not a truck or a van.
The term URL has been used so ubiquitously when referring to URI the term URL is now acceptable. However, it is advised to always use the term URI if a difference matters in any significance.
To further understand the concept of a URI let’s now say we want to locate a book. But don’t know where the book is located? We could not use a URL since a URL is host specific. We could, however, use a URN:
urn:isbn:045145032
When using a URN as depicted, an underlying web application is tasked with the business-logic of locating a requested document.
Let’s say in our analogy a URN is a van, another specific type of automobile. A URI defines a URN and URL. A URN identiies a specific resource, in our example a book. While a URL identifies location and other means for accessing a resource. Pretty simple, heh?
Dissecting a URL
A URL, otherwise known as a Uniform Resource Locator is the most common URI in use on the world wide web. This is what we enter into the address bar of a web browser to get https://www.google.com.
Let’s take a look at more complex URL and break each part down:
http://admin:password@web5.acmeco.com:8080/admin-docs/2017/ins/infrastructure.xlsx
Now this one can take some explaining and is 100% valid (kind of valid. Please see below).
Usin credentials for authentication in the URL is considered a depreciated standard. Some browsers still support using credentials in a URL but is still considered extremely poor security practice
| URL Credentials | |
| scheme | http:// |
| credentials | admin:password |
| resource/host | web5.acmeco.com |
| port | 8080 |
| path | admin/docs/2017/ins/ |
| document | infrastructure.xlsx |
http://www.amcmeco.com/ is also a valid URL.
The appended forward slash tells the web-server we want the default document in the webroot. Traditionally this is document is named index.html but can be modified to anything by server’s Administrator.
Another valid URL can be: mailto://billgates@microsoft.com. Instead of requesting a document, this URL will open the default mail client ready to type a letter to Mr. Gates at microsoft.com (if the email address is valid of course).
Some valid URL protocol schemes are: telnet://, gopher://, ftp://, https://, mailto://, file://, irc://, and probably a few more. http and https are the most commonly used protocols on the world wide web, however.
Query Strings
Another common way for specifying a URL exists and is commonly used on the world-wide-web. It is called a query string. A query string is usually used in conjunction with a back-end web-application or a CGI script.
An example is appended to our previous GET request directly accessing Google Search:
https://www.google.com/search?q=euro+vps
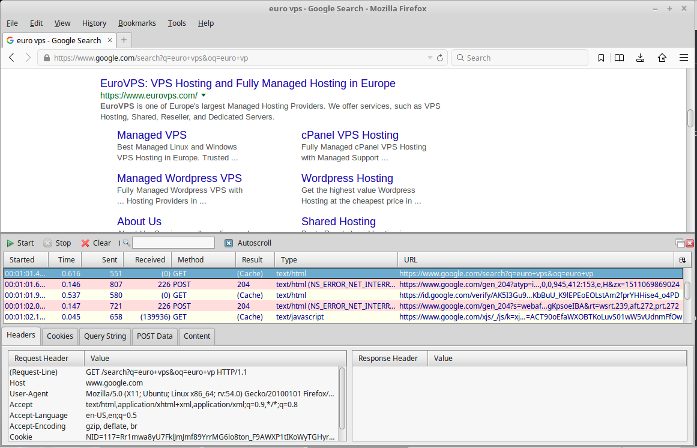
Looking behind the scenes in HTTPFox at our GET request with a valid query string appended
Query strings are usually used for passing parameters to a backend script. The Query string is encoded by the web-browser, then delivered to a web-server, decoded by the web server or application, then finally processed by the web-application.
Query strings have been known to be exploited by passing bad parameters in attempts to manipulate functionality of a web application.
https://www.acmeco.com/auth/auth.php?user=acmeuser&password=054fd31356a02e672a4ee1ebb0bce5fa
Above is an example of a really insecure way of using a query string. At the least, hashed passwords will be stored in HTTP logs and could allow an easy method to brute-force user accounts.
HTTP Verbs
Now that we have a good idea of what a URL is and how query strings are used, we will introduce verbs used for HTTP Requests. The most commonly used HTTP verbs are:
- POST & GET
- PUT
- DELETE
- HEAD
- TRACE
- OPTIONS
- CONNECT
1.POST and GET
GET is the default method used when typing a website into a web-browser’s address-bar of or clicking a hyperlink. When a webpage is requested, the web-browser can actually make several GET or POST requests downloading all resources composing a webpage including images, stylehseets, client-side scripts, typography resources, and more:
hyperlink is the technical name for linking to secondary webpages. When the user clicks on a link (or hyperlink), the webbrowser sends a GET request for the linked page
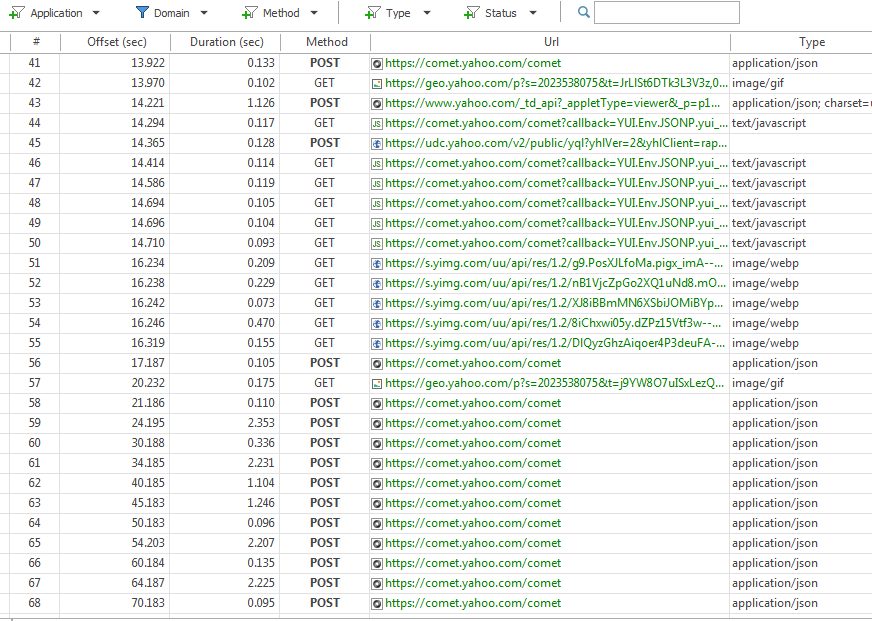
Typing www.yahoo.com to request the default page from yahoo.com initiates many HTTP GET and POST requests.
POST Requests
The two most commonly used request methods are GET and POST. We have already broken down a GET request. So let’s examine a POST request.
What if we wanted to upload a 1GB file via a PHP or asp script? Naturally, a URL cannot hold a 1GB binary string. We would use the POST method in this scenario.
POST is similar to GET in that POST can pass parameters like a query string. However, POST data is not appended to a URL like with the query string.
Instead, POST parameters are passed in the header section of the HTTP request. POST is most commonly used with HTML form data.
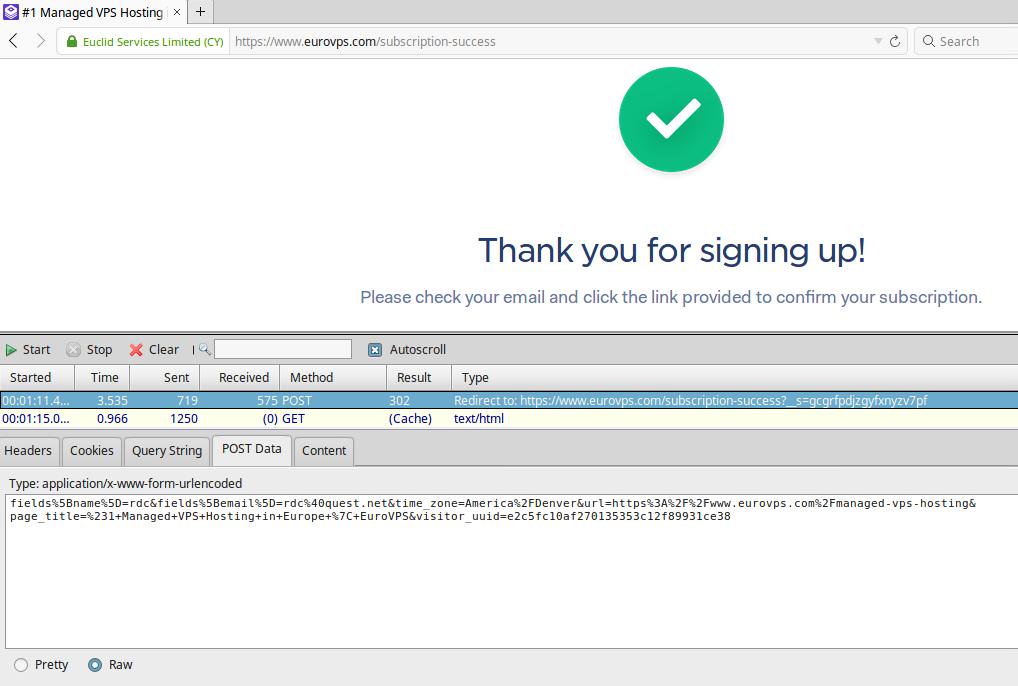
A POST submission signing up to the Euro VPS mailing list
If you’d like to sign up for our mailing list and give it try you, go to our homepage and subscribe at the bottom page: Euro VPS Home Page
The POST method is commonly used when the following features are needed:
- file uploads
- nondisclosure of sensitive data
- longer data strings need to be sent
- different encoding schemes must be used
- cannot be cached (if a security concern)
Let’s compare with some advantages of the GET method with a query string appended to the URL
- can be saved as a bookmark
- can be cached
- query results can be shared with a link
2. PUT
The PUT method is most often used in RESTful web API’s. PUT is generally used to modify objects – while a POST is used to create objects in a web API.
PUT is usually disabled by default on web server installations.
Leaving PUT enabled could potentially allow attackers the ability to upload and executing files on the web server.
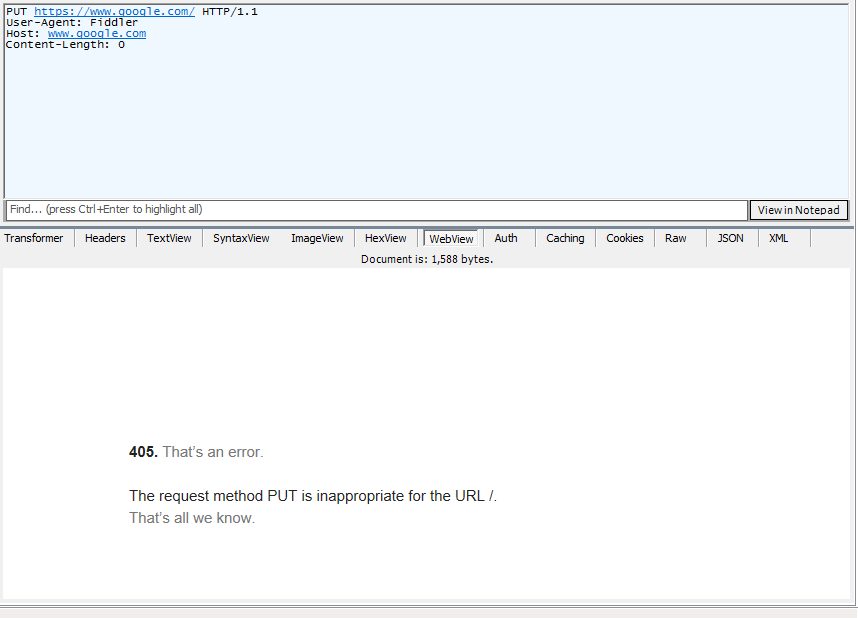
A PUT request to http://google.com is denied with an HTTP 405 Error Code.
3. DELETE
Like PUT the DELETE method is most commonly used in RESTful API’s. Using DELETE should perform a delete action on a URI object:
DELETE is disabled by default on most web server installations. Enabling DELETE when unneeded could be a security risk allowing attackers to delete documents from a website.
4. HEAD
The HEAD method is a similar method to GET but returns only headers with no content. HEAD is commonly used to check if a cached document has been updated. Retrieving headers is much faster than receiving content. If the document is newer than a cached version the entire document will be downloaded and cached.
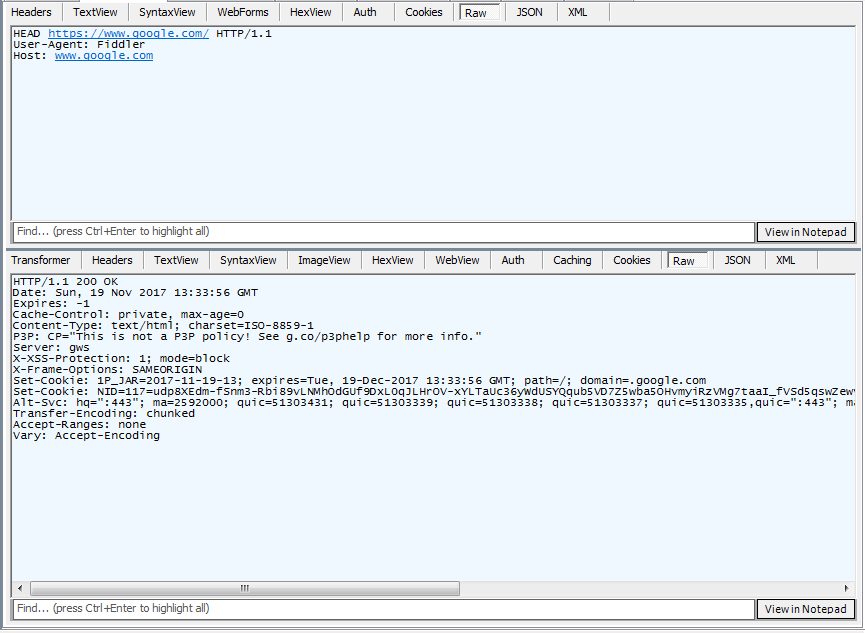
The same request to Google using HEAD instead of GET
5. TRACE
TRACE is a diagnostics method and will usually be disabled on most web-servers. Many security researchers have discovered potential vulnerabilities with TRACE methods. Liability by far outweighs usefulness with TRACE most times.
6. OPTIONS
Will return methods enabled on a web-server. Such as POST, GET, TRACE, PUT, and DELETE. OPTIONS should be disabled as well. Disabling OPTIONS is considered best practice so attackers cannot scan for vulnerable servers supporting TRACE, CONNECT PUT and DELETE
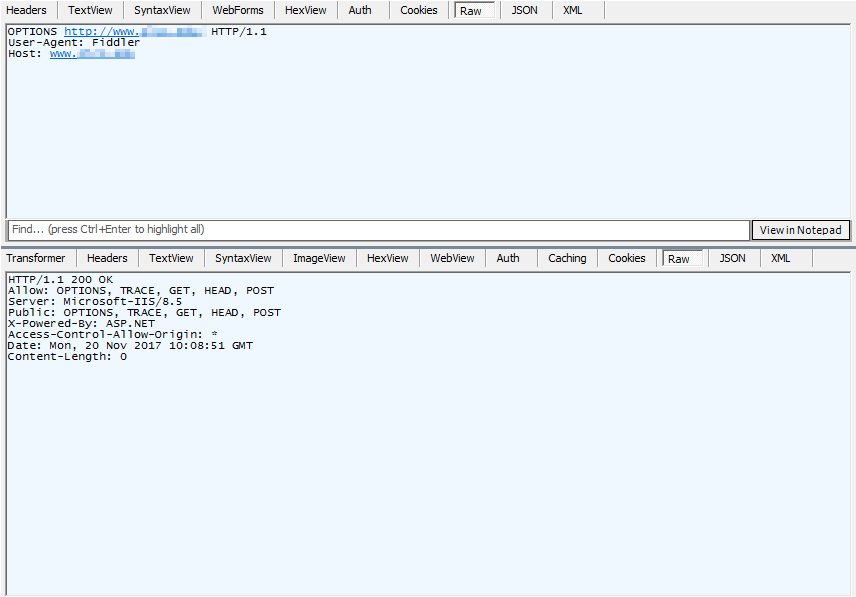
Poorly configured web-server supporting both OPTIONS and TRACE
7. CONNECT
It is seldom used and considered a security issue like PUT, DELETE, TRACE, and OPTIONS. CONNECT, when enabled and misconfigured can allow connections to proxy requests to other servers. These proxied connections can be used for attacks or downloading illegal files.
By default, the most web server software will have CONNECT disabled.
Legitimate CONNECT usage is for forwarding proxying HTTPS and allowing SSH tunnels to connect. The CONNECT has not seen a lot anymore and should be used sparingly.
Media Types
A Media Type defines files based on nature and format for display or processing. The Content-Type header is used in an HTTP response allowing a web-browser to display response text, load a plugin for a supported filetype, or simply download a file for viewing in a different application.
Originally Media Type was implemented for email attachments and coined MIME Types. MIME stands for Multipurpose Internet Mail Extension.
Some Media-Types may be prefixed with a “x-“ or a “vnd”. The “x” means a Media Type is not officially listed by IANA (Internet Assigned Numbers Authority). The “vnd” portion means a Media-Type is vendor specific (for example a Microsoft Active-X ).
Viewing Media-Types in Firefox
- type “about:config” in the address bar.
- in the configuration search box type “mime”
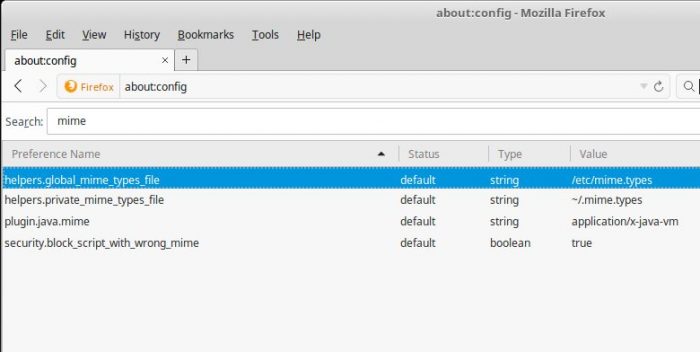
On a Linux platform we can see Firefox uses the file /etc/mime.types
Let’s take a look at a portion of our /etc/mime.types file:
rdc@debain ~ $ head -n 40 /etc/mime.types | egrep -v "^#"
application/activemessage
application/andrew-inset ez
application/annodex anx
application/applefile
application/atom+xml atom
application/atomcat+xml atomcat
application/atomicmail
application/atomserv+xml atomsrv
application/batch-SMTP
application/bbolin lin
application/beep+xml
application/cals-1840
application/commonground
application/cu-seeme cu
application/cybercash
rdc@mint ~ $ wc -l /etc/mime.types
835 /etc/mime.types
rdc@debian ~ $
As shown, over 800 specific mime-types are recognized by this system. In essence this tells Firefox about extensions associated with certain filetypes.
NOTE: Media-Types are different from the operating system “default applications”. While similar in concept, mime types are used for internet-aware applications while an operating system keeps a separate record of filetypes and associated viewers.
When a GET request is made for an Excel spreadsheet, the Content-Type header returns application/vnd.ms-excel. In turn, the web-browser knows the file should not be displayed as text in the browser window. Instead, the file is either loaded into a plugin viewer or downloaded for later viewing in a different application.
A Unix or Linux web-server also uses /etc/mime.types for the Content-Type header. In addition a mime-type used for scripting in a language such as php must be specified as a special mime type reserved for pre-processing.
debian#> cat php7.0.conf
1 <FilesMatch ".+\.ph(p[3457]?|t|tml)$">
2 SetHandler application/x-httpd-php
3 </FilesMatch>
<FilesMatch ".+\.phps$">
SetHandler application/x-httpd-php-source
# Deny access to raw php sources by default
# To re-enable it's recommended to enable access to the files
# only in specific virtual host or directory
Require all denied
</FilesMatch>
# Deny access to files without filename (e.g. '.php')
<FilesMatch "^\.ph(p[3457]?|t|tml|ps)$">
Require all denied
</FilesMatch>
# Running PHP scripts in user directories is disabled by default
#
# To re-enable PHP in user directories comment the following lines
# (from <IfModule ...> to </IfModule>.) Do NOT set it to On as it
# prevents .htaccess files from disabling it.
<IfModule mod_userdir.c>
<Directory /home/*/public_html>
php_admin_flag engine Off
</Directory>
</IfModule>
debian#>
Above: lines one -to- three specify file extensions beginning with “.php” are sent to the PHP interpreter.
If you have ever clicked a link only to have a graphic or other binary data displayed as ASCII by your web-browser or have been prompted to download a web-page – it means the browser or server mime-types were misconfigured.
To trouble-shoot look at the Content-Type Header in a tool such as HTTPFox:
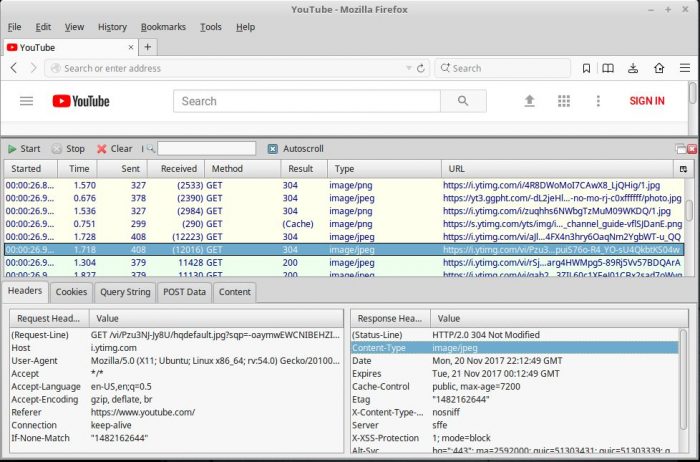
We can see the correct content-type was specified in a server response*. If the browser were prompting to save the requested image from the get request, we’d know the browser mimetype for image/jpeg needs to be reconfigured.
Improper configurations of server-side-scripting or binary mime-types can lead to security issues on the server or client.
IANA – Internet Assigned Numbers Authority is tasked with keeping an official mapping of media-types through RFC status.
HTTP Characteristics
In this section, we will discuss characteristics of the HTTP protocol. The most important concepts to know when working with HTTP are:
- HTTP is stateless and connectionless
- HTTP does not offer built-in encryption
What is a Stateless, Connectionless Protocol?
HTTP is connectionless as a result of being stateless. Stateless and connectionless are by design of the HTTP protocol.
Stateless simply means HTTP transactions are requested by a user-agent then responded to by the web-server. If a client doesn’t cache requested resources it must then issue the same method to again obtain the resource. An HTTP web server has no state table to lookup previous communications with a user-agent.
HTTP Cookies: cookies can assist a web-server in referencing past HTTP interactions with a user-agent. However, this is not stateful. A new connection separate in every way from previous transactions must be initiated.
Most back-end programming languages such as Python’s Django Framework, PHP, and ASP .Net offer libraries for maintaining application state with built-in session frameworks. This approach does add statefulness to a web-application, but is abstracted at a higher level than HTTP.
HTTP Does Not Provide Encryption
HTTP itself does not provide built-in encryption mechanisms. Encryption is left to other protocols defining HTTPS. HTTPS uses Transport Layer Security or TLS, the successor to SSL.
TLS works with many protocols – not just HTTP. HTTPS is designed for carrying HTTP content-data and HTTP headers over secured TLS connections. SSL was originally developed in the 1990’s by Netscape. SSL technologies have been transferred to the Internet community and re-labeled as TLS avoiding intellectual property violations.
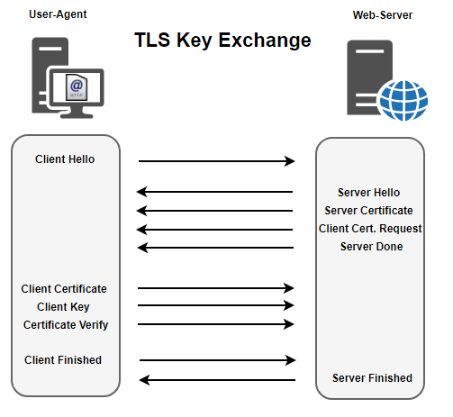
TLS Key Exchange
The astute reading may wonder, “So HTTPS is stateful? Right? Each session does have a key? Right?”. Keys are cached by the client, yes. But TLS is still functioning at a lower layer than the HTTP core of HTTPS. Interactions with the web-server are still using the same HTTP Methods: GET, POST, PUT, and DELETE.
HTTP Authentication
Authentication, unlike encryption, is built into HTTP. HTTP supports multiple types of authentication types including:
- Basic
- Bearer
- Digest
- HOBA
- Mutual
- Negotiate
- OAuth
- SCRAM-SHA1
- SCRAM-SHA256
- vapid
Basic Authentication
By far the most common method of HTTP authentication is Basic Authentication. A myriad of Basic Authentication deployments does not mean Basic Authentication is the most secure. Basic Authentication is mostly a go-to choice based on the simplicity of implementation. Other authentication schemes are far more secure, especially when not running over TLS/SSL.
The greatest security issue with Basic Authentication is that credentials are being set in clear-text. While credentials are encoded using Base-64, encoding is not encryption but is obfuscated at best. Credentials can easily be compromised when not using TLS or when TLS web-traffic falls victim to a man-in-the-middle attack.
Basic Authentication Shortcomings:
- encodes credentials in BASE 64 only
- credentials are cached in browser leaving another attack vector
- credentials can be permanently stored in the browser
- rogue proxy servers can potentially log credentials
- credentials are in the HTTP header
BASIC Authentication still does still serve a purpose. However, limitations of that purpose are important to acknowledge. Basic Authentication is good for access control only. Access Control is simply meant for controlling access to resources. Basic Authentication is not good for securing data. Especially sensitive information which has the potential of equating into the loss of revenue or a loss of privacy upon exposure.
When implementing an HTTP authentication scheme think of Basic Authentication as a key code allowing authorized entry into a building or office only when security staff is onsite. After business hours, the same doors are locked with a more secure mechanism to secure the building.
- access control is convenient access to authorized personnel
- security keeps property secure from attackers
Below is an illustration of a Basic Authentication request/response:
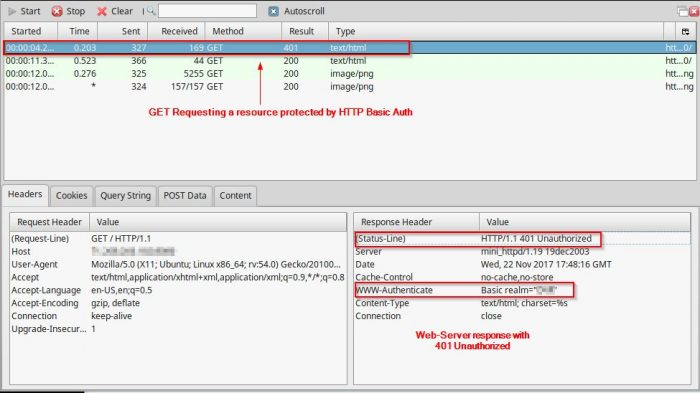
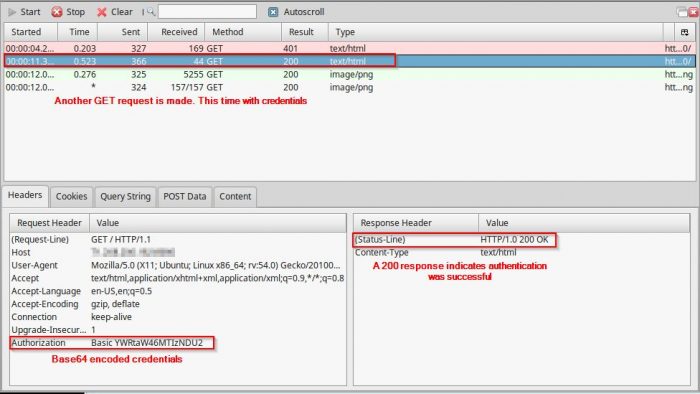
- User-Agent makes a request for a document
- Web-Server responds with HTTP Code 401: Authorization Required
- User-Agent responds with supplied with credentials
- Web-Server allows or denies access based on credential validity
As a demonstration of Basic Authentication shortcomings, try figuring out credentials from the depicted BASE64 encoded string.
Bearer Token Based Authentication
Bearer Token Based authentication is popular amongst authentication framework providers. Bearer Authentication can also be deployed as a stand-alone, per instance solution.
Bearer Authentication is based on tokens and used in both OAuth and OpenID frameworks. Typically OAuth is used for authorization while OpenID is for Authentication. However, several gray areas exist blurring the lines of Authentication and Authorization in each framework.
- OpenID provides federated authentication or login services
- OAuth provides delegated authorization
3rd Parties can access GitHub resources with OAuth
GitHub provides an OAuth Guide for developers of 3rd party applications wishing to access GitHub resources on behalf of an end-user. GitHub OAuth App Guide
OpenID has been adopted by many heavyweight, online content providers:
Yahoo supports OpenID, using your Yahoo identity as validation for much other content providers.
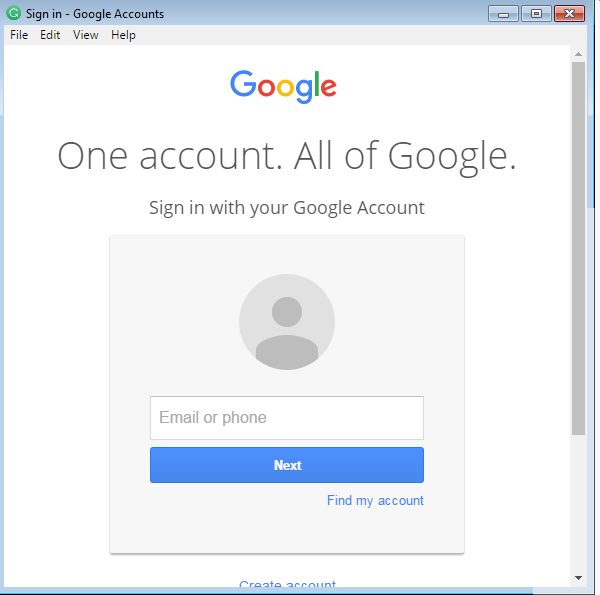
Login Using OpenID with a Google Account:
Facebook is not an OpenID provider but offers Open Connect as a rival to OpenID
Digest Authentication
Digest Authentication is more secure than Basic Authentication. However, Digest Authentication is still inadequate at securing sensitive material on the Internet. While Digest Authentication does encrypt credentials if encrypted/hashed credentials are obtained an attacker can launch an offline brute-force or dictionary attack.
Both Digest and Basic authentication schemes are considered weak in the grand scheme of data security. Each has faults and each has been successfully attacked. When more than basic access control or authorization is needed a more secure authentication scheme must be deployed.
Other HTTP Based Authentication Schemes
NTLM known as NT Lan Manager Authentication is a Microsoft technology with plugins for many 3rd party products, operating systems, and services.
NTLM Authentication V2 is the preferred choice for Corporate Windows Domains. NTLM uses Active Directory credentials with SSPI and Kerberos. This means domain users previously authenticated have the ability to access authorized resources without entering additional credentials. Also, all authentication within the Corporate Windows Domain realm is performed with Kerberos tickets and challenge/response authentication mechanisms.
The biggest drawbacks to NTLM based authentication are infrastructure – can be cumbersome to implement on platforms other than Windows
- can lose a lot of security features if deployed outside a Windows Domain
- NTLM is only secure as the corporate network
- Older versions of NTLM are considered insecure
SCRAM-SHA1 & SCRAM-SHA256
SCRAM is an acronym for Salted Challenge Response Mechanism
When needing to authenticate internal employees SCRAM Authentication coupled with OpenLDAP may be a good solution for heterogeneous vendor environments.
SCRAM can be more sophisticated to deploy than NTLM for a Windows Domain. But SCRAM can be a great choice on a network with Linux, MacOS Server, Windows and Unix clients and even over the Internet.
Configuring SCRAM based authentication in a secure manner will require a technical staff with good grasps on I.T. infrastructure and technologies such as Application layer development, HTTP, HTTPS, TLS, SCRAM Authentication, OpenLDAP, SASL, PKI infrastructure and more
SCRAM authentication is well purposed for securing web-resources outside and inside a corporate LAN but will require an investment in both IT Staffing and infrastructure.
Next.

Ultimate Guide Understanding HTTP Status Codes – 300 Series. HTTP 300 status codes are reserved for redirects. Most redirects will be transparent to the end-user and are handled entirely by a user-agent.
Read More
Thomas
Bash scripting enthusiast who can also cook up a pretty amazing lasagna. If you don't find me in the datacenter or in deep thought troubleshooting customer tickets, well... You're probably not looking hard enough!
Ultimate Guide to Understanding HTTP Status Codes 500 – Internal Service Error

Before delving into a detailed technical discussion of cause behind 500 error code, it is important to understand what t...
Thomas
12 Dec 2017 10min read 500
Ultimate Guide Understanding HTTP Status Codes – 300 Series

HTTP 300 status codes are reserved for redirects. Most redirects will be transparent to the end-user and are handled ent...
Thomas
12 Dec 2019 10min read 300
Ultimate Guide to Understanding HTTP Status Codes – 400 Series

400 series request codes deal with malformed and unserviceable requests from a user-agent. Whenever a 400 series is enco...
Thomas
12 Dec 2017 14min read 400